Felix Lohmeier, Weimar, 27.05.2026
Die Weimarer Systemarchitektur und ihre neuen Normdaten-Funktionen
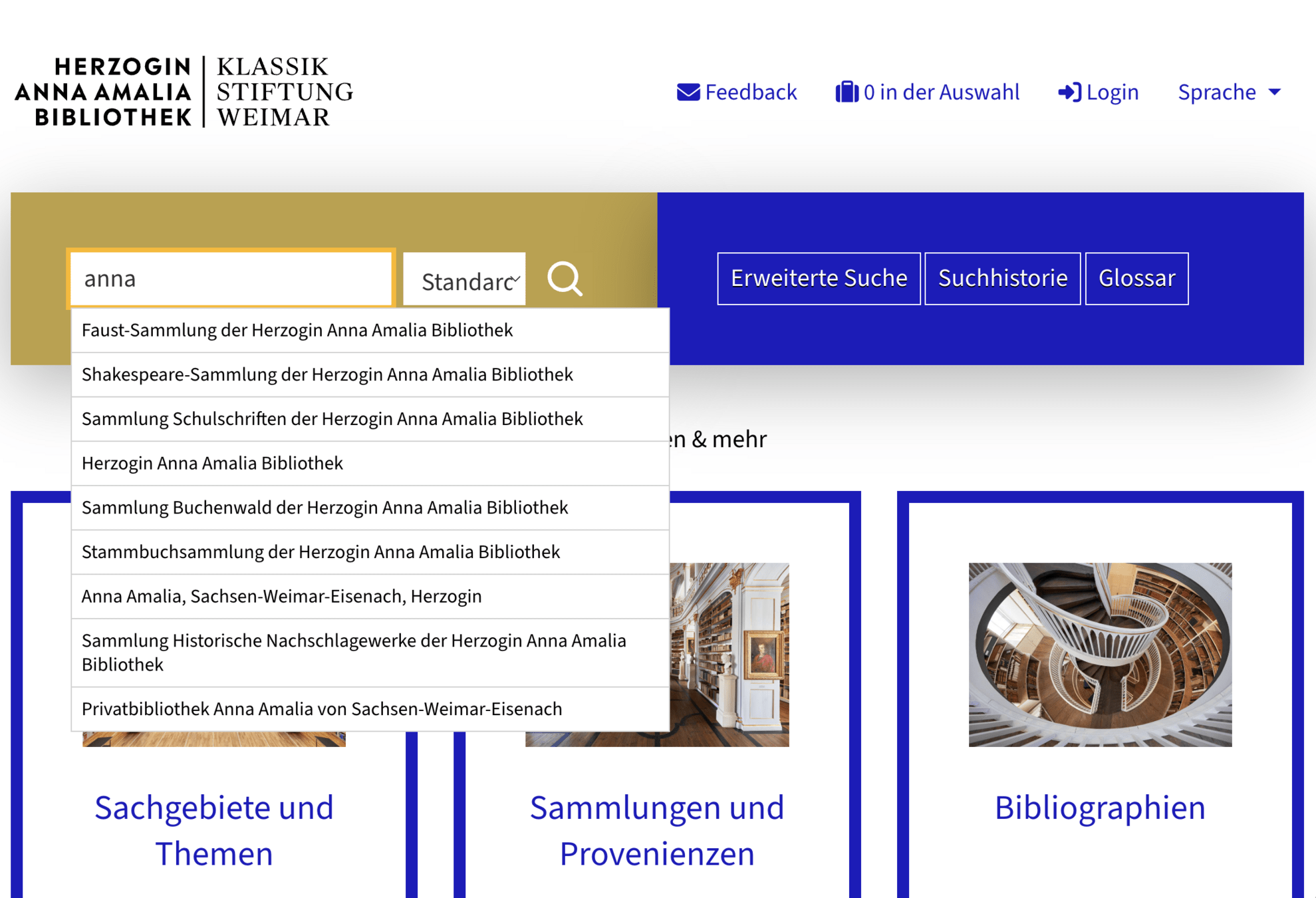
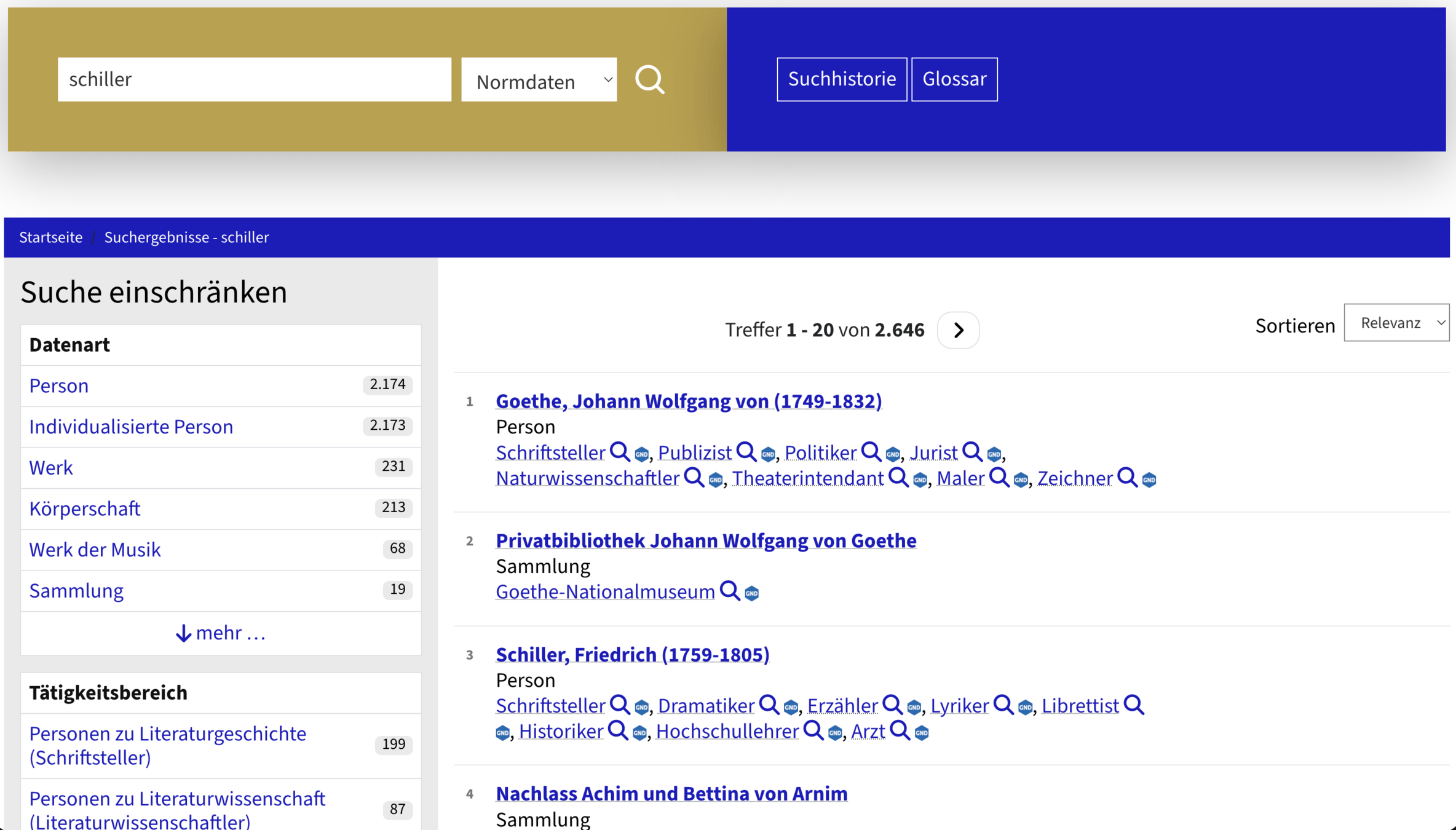
Suchbegriff: nietzsche
Suchtyp: Verfasser/Urheber
Spezifische Suchvorschläge aus dem Normdatenindex sortiert nach Anzahl der Verknüpfungen
Normdaten im Suchschlitz
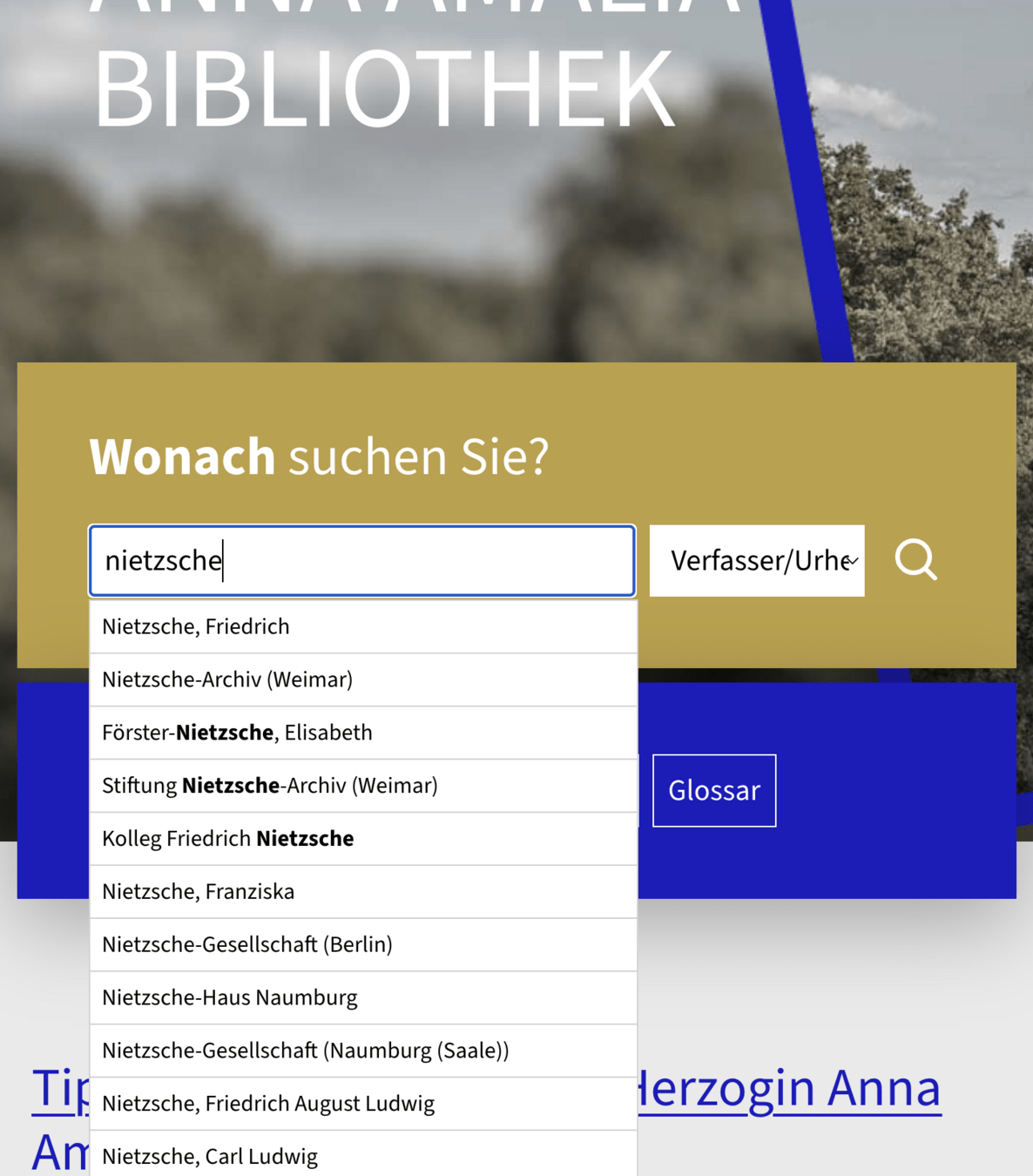
Suchbegriff: privatbibliothek
Suchtyp: Provenienz/Sammlung
Spezifische Suchvorschläge aus dem Normdatenindex sortiert nach Anzahl der Verknüpfungen
Normdaten im Suchschlitz

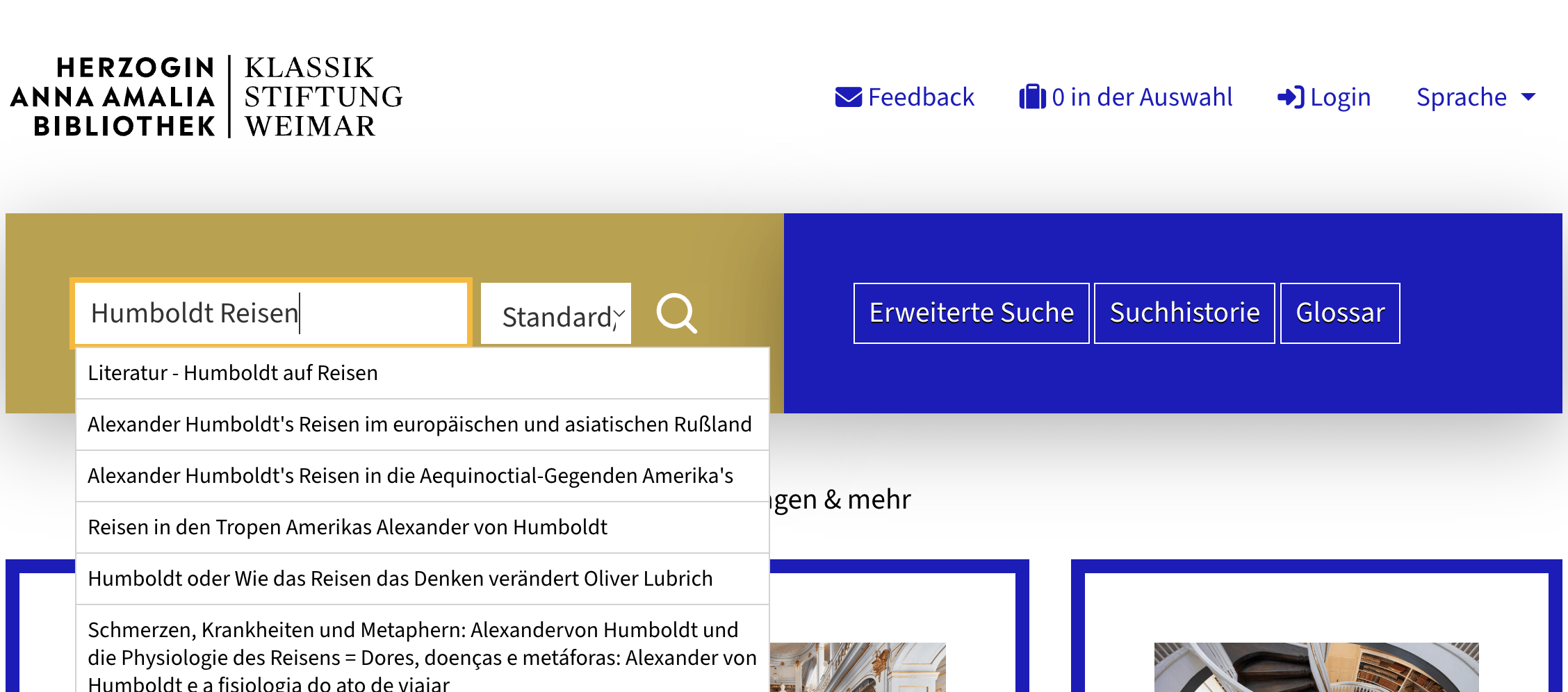
Normdaten als Werbetreffer
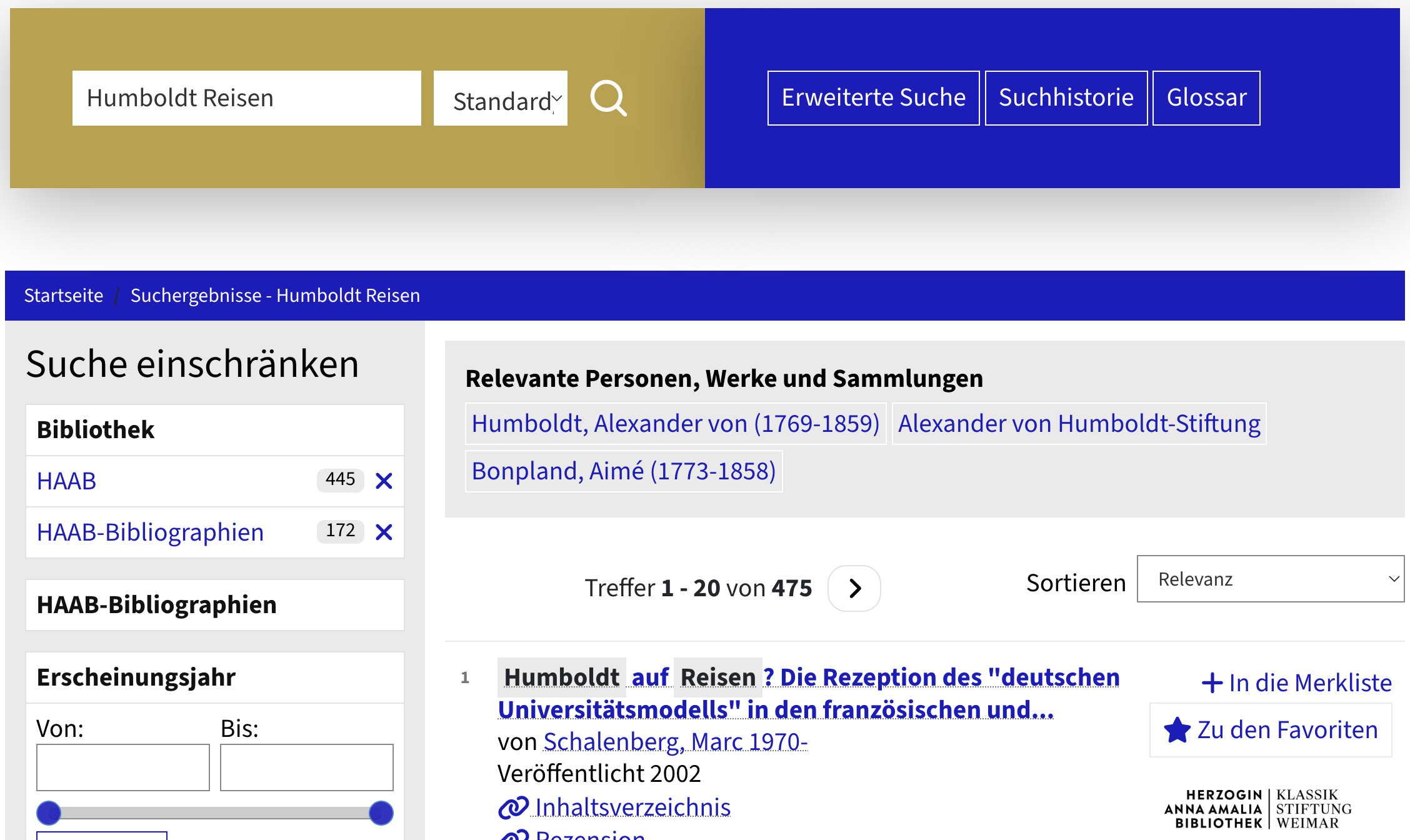

Normdaten als Wegweiser

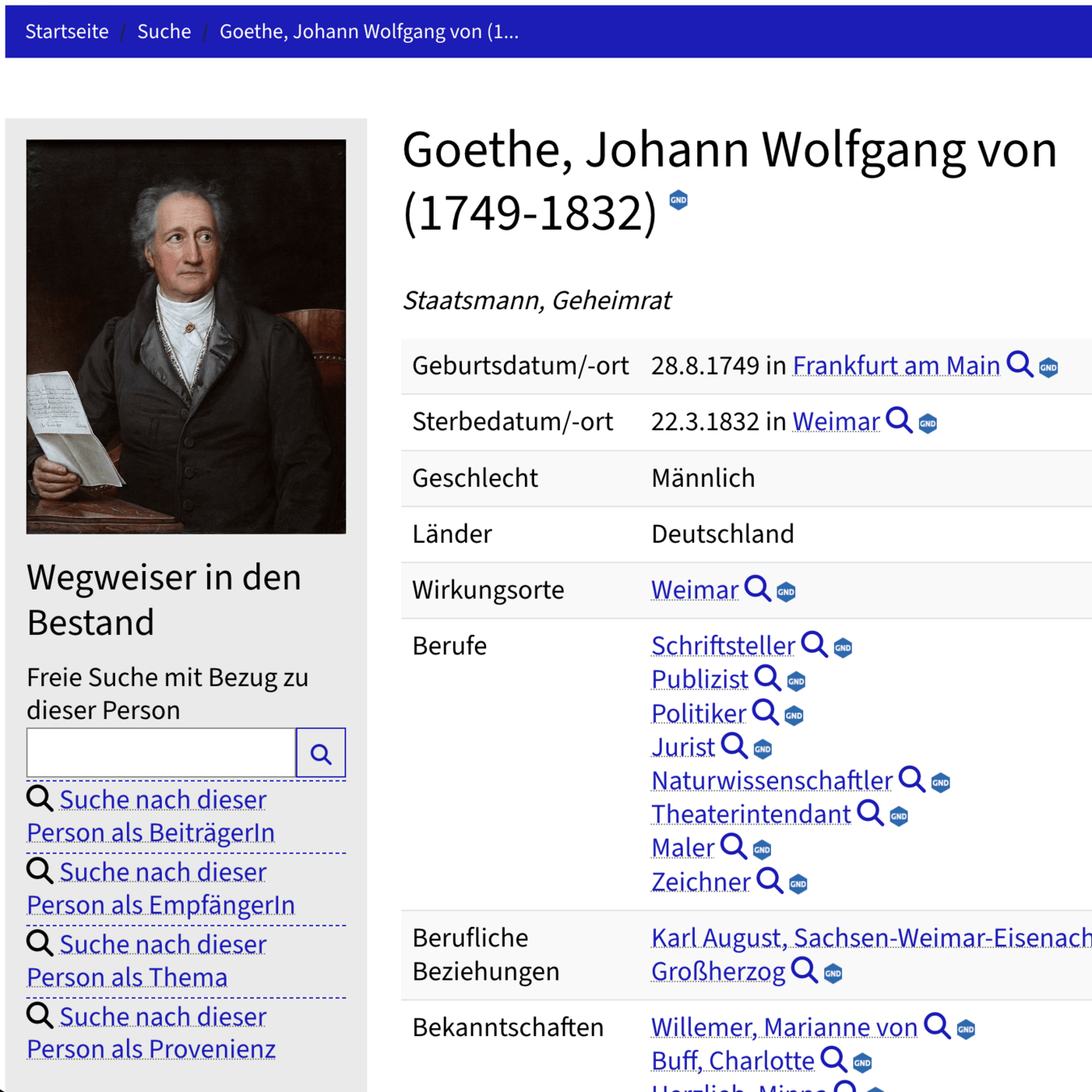
🏛️ Körperschaft
lobid-gnd: 1.572.207
HAAB: 56.492
Normdaten als Wegweiser
👤 Person
lobid-gnd: 6.616.122
HAAB: 426.140

Normdaten als Wegweiser
📖 Werk (ohne Sammlung)
lobid-gnd: 607.185
HAAB: 32.196

Normdaten als Wegweiser
🗄️ Sammlung
lobid-gnd: 1.783
HAAB: 519

Normdaten als Wegweiser
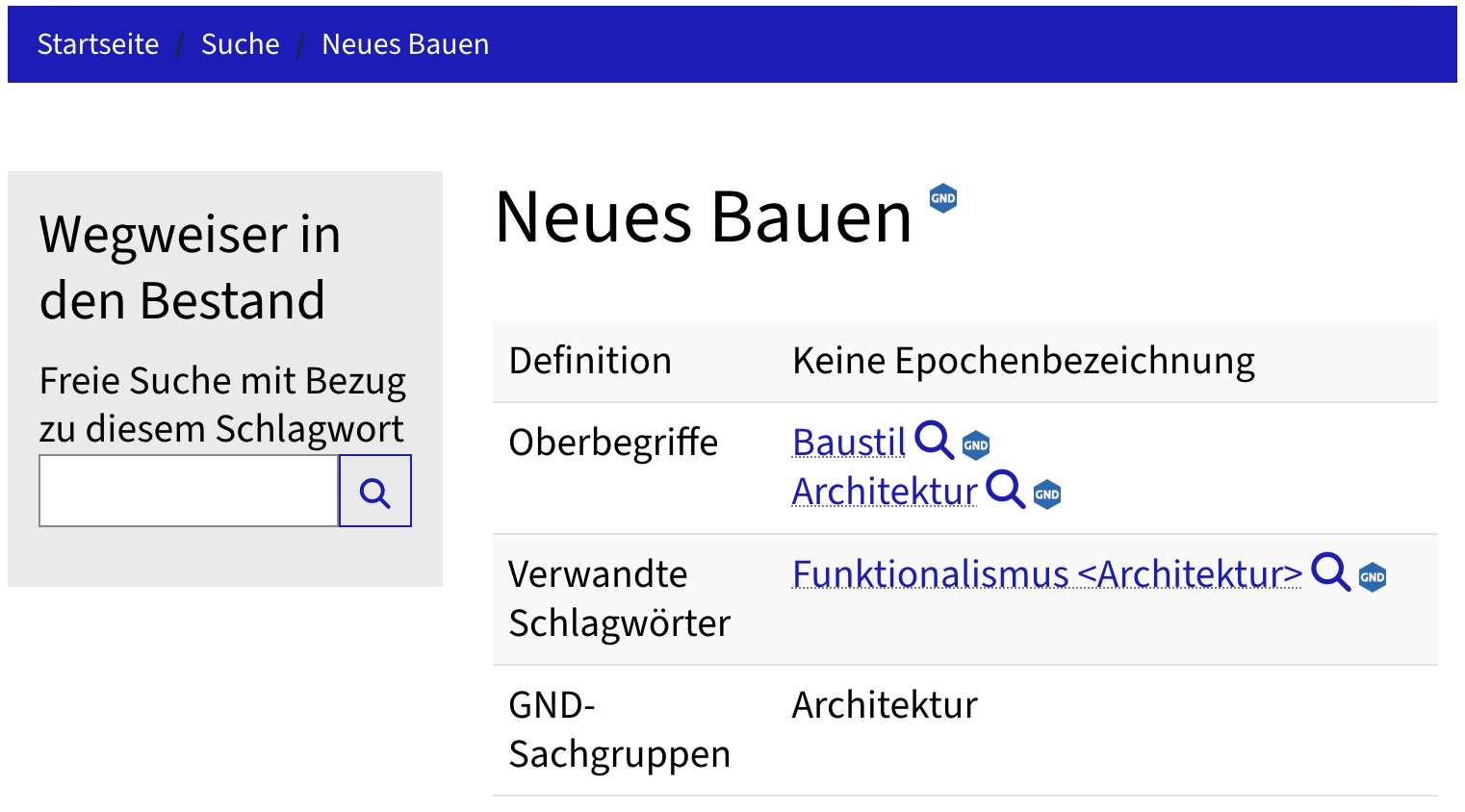
🌐 Geografikum
lobid-gnd: 337.603
HAAB: 23.147
Normdaten als Wegweiser
#️⃣ Schlagwort
lobid-gnd: 208.379
HAAB: 43.726
Suche in Normdaten

👤 Person
lobid-gnd: 6.616.122
HAAB: 426.140
Normdatenindex der HAAB
🏛️ Körperschaft
📖 Werk (ohne Sammlung)
🗄️ Sammlung
lobid-gnd: 1.783
HAAB: 519
🌐 Geografikum
#️⃣ Schlagwort
lobid-gnd: 1.572.207
HAAB: 56.492
lobid-gnd: 607.185
HAAB: 32.196
lobid-gnd: 337.603
HAAB: 23.147
lobid-gnd: 208.379
HAAB: 43.726

powered by
Systemarchitektur
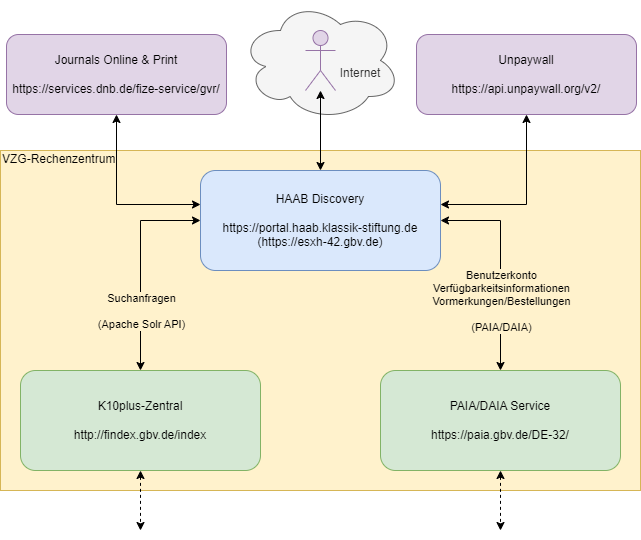
Systemarchitektur:
ETL-Prozess
- K10plus-Zentral abfragen
- GND-Daten von lobid-gnd herunterladen
- Heruntergeladene Daten auf Bestand der HAAB filtern
- Gefilterte Daten in VuFind-Schema transformieren
- Transformierte Daten in lokalen Solr Index laden

flowchart TD
subgraph SOURCES["Quellen"]
K10["K10plus-Zentral"]
LOBID["lobid-gnd"]
end
subgraph ETL["ETL-Pipeline"]
S2["Filter"]
S3["Transform"]
end
subgraph TARGET["Solr"]
SOLR[("Lokaler Normdatenindex")]
end
K10 -->|"Von HAAB verwendete GND-IDs"| S2
LOBID -->|"Komplett-Download der GND"| S2
S2 -->|"HAAB-relevante Normdatensätze"| S3
S3 -->|"VuFind-Schema"| SOLRCode: Abfrage GND-IDs K10plus-Zentral
import urllib.request
import json
import gzip
from io import BytesIO
# Normlink-Abfrage
normlink_uri = 'http://findex.gbv.de/index/61_2/select?q=*&rows=0'
normlink_uri += '&fq=collection_details:%28%22GBV_ILN_61%22%20OR%20%22GBV_ILN_288%22%29'
normlink_uri += '&facet=true&facet.limit=-1&facet.field=normlink_prefix_str_mv&facet.prefix=%28DE-588%29&facet.mincount=1'
normlink_req = urllib.request.Request(normlink_uri, headers={'Accept-Encoding': 'gzip'})
with urllib.request.urlopen(normlink_req) as response:
if response.getheader('Content-Encoding') == 'gzip':
buf = BytesIO(response.read())
with gzip.GzipFile(fileobj=buf) as gz:
normlink_data = json.load(gz)
else:
normlink_data = json.load(response)
normlink_array = normlink_data['facet_counts']['facet_fields']['normlink_prefix_str_mv']
normlink_dict = {normlink_array[i][8:]: normlink_array[i+1] for i in range(0, len(normlink_array), 2)}
# Provenance-Abfrage
provenance_uri = 'http://findex.gbv.de/index/61_2/select?q=*&rows=0'
provenance_uri += '&fq=collection_details:%28%22GBV_ILN_61%22%20OR%20%22GBV_ILN_288%22%29'
provenance_uri += '&facet=true&facet.limit=-1&facet.field=provenience_isil_gnd_str_mv&facet.prefix=DE-32%40%28DE-588%29&facet.mincount=1'
provenance_req = urllib.request.Request(provenance_uri, headers={'Accept-Encoding': 'gzip'})
with urllib.request.urlopen(provenance_req) as response:
if response.getheader('Content-Encoding') == 'gzip':
buf = BytesIO(response.read())
with gzip.GzipFile(fileobj=buf) as gz:
provenance_data = json.load(gz)
else:
provenance_data = json.load(response)
provenance_array = provenance_data['facet_counts']['facet_fields']['provenience_isil_gnd_str_mv']
provenance_dict = {provenance_array[i][14:]: provenance_array[i+1] for i in range(0, len(provenance_array), 2)}
# Alle GND-IDs aus beiden Quellen
all_gnd_ids = set(normlink_dict.keys()) | set(provenance_dict.keys())
results = []
for gnd_id in sorted(all_gnd_ids):
normlink_count = int(normlink_dict.get(gnd_id, 0))
provenance_count = int(provenance_dict.get(gnd_id, 0))
total_count = normlink_count + provenance_count
provenance = 'true' if gnd_id in provenance_dict else 'false'
results.append(f"{gnd_id}\t{total_count}\t{provenance}")
print('\n'.join(results))Code: Bulk-Download von lobid-gnd
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:Collection&format=jsonl' \
| gzip > lobid-collection.jsonl.gz
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:ConferenceOrEvent&format=jsonl' \
| gzip > lobid-conference.jsonl.gz
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:CorporateBody&format=jsonl' \
| gzip > lobid-corporate.jsonl.gz
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:Family&format=jsonl' \
| gzip > lobid-family.jsonl.gz
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:Person&format=jsonl' \
| gzip > lobid-person.jsonl.gz
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:PlaceOrGeographicName&format=jsonl' \
| gzip > lobid-geo.jsonl.gz
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:ProvenanceCharacteristic&format=jsonl' \
| gzip > lobid-provenance.jsonl.gz
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=type:SubjectHeading&format=jsonl' \
| gzip > lobid-subject.jsonl.gz
# Restliche Werk-Datensätze ohne zuvor bereits geladene Collection und ProvenanceCharactistic
curl -A "HAAB Discovery" -s --compressed 'https://lobid.org/gnd/search?q=NOT+%28type%3ACollection+OR+type%3AProvenanceCharacteristic%29&filter=%2B%28type%3AWork%29&format=jsonl' \
| gzip > lobid-work.jsonl.gzCode: GND-Download filtern
#!/usr/bin/env python3
import argparse
import gzip
import json
import os
import sys
parser = argparse.ArgumentParser(description='Filter GZIP-komprimierte JSONL-Datei basierend auf einer Liste von GND-IDs')
parser.add_argument('jsonl_file', help='Pfad zur GZIP-komprimierten JSONL-Datei')
parser.add_argument('tsv_file', help='Pfad zur TSV-Datei mit GND-IDs in der ersten Spalte, Zähler in der zweiten Spalte und Provenance (true/false) in der dritten Spalte')
args = parser.parse_args()
if not os.path.exists(args.jsonl_file) or not os.path.exists(args.tsv_file):
print('Eine der Eingabedateien wurde nicht gefunden.', file=sys.stderr)
exit(1)
# Nur bestimmte Felder übernehmnen
fields = [
'accordingWork',
'biographicalOrHistoricalInformation',
'collector',
'contributingPerson',
'formerOwner',
'geographicAreaCode',
'gndIdentifier',
'homepage',
'owner',
'placeOfCustody',
'precedingWork',
'preferredName',
'relatedPerson',
'relatedPlaceOrGeographicName',
'relatedWork',
'sameAs',
'succeedingWork',
'topic',
'type',
'variantName'
]
# GND-IDs, Zähler und Provenance aus der TSV-Datei einlesen
with open(args.tsv_file, 'r', encoding='utf-8') as f:
gnd_info = {}
for line in f:
if line.strip() and '\t' in line:
parts = line.strip().split('\t')
gnd_id = parts[0]
normlink_count = parts[1]
provenance = parts[2].lower() == 'true' if len(parts) > 2 else False
gnd_info[gnd_id] = (normlink_count, provenance)
# JSONL-GZIP-Datei filtern
with gzip.open(args.jsonl_file, 'rt', encoding='utf-8') as infile:
for line in infile:
record = json.loads(line)
gnd_id = record.get('gndIdentifier')
if gnd_id in gnd_info:
filtered_record = {key: record[key] for key in fields if key in record}
filtered_record['normlinkCount'] = gnd_info[gnd_id][0]
filtered_record['provenance'] = gnd_info[gnd_id][1]
print(json.dumps(filtered_record, ensure_ascii=False))Code: Transformation in VuFind Schema
#!/usr/bin/env python3
import argparse
import pandas as pd
import json
import os
import sys
parser = argparse.ArgumentParser(description='Transformiere GZIP-komprimierte JSONL-Datei')
parser.add_argument('jsonl_file', help='Pfad zur GZIP-komprimierten JSONL-Datei')
parser.add_argument('tsv_file', help='Pfad zur TSV-Datei mit GND-IDs in der ersten Spalte, Zähler in der zweiten Spalte und Provenance (true/false) in der dritten Spalte')
args = parser.parse_args()
if not os.path.exists(args.jsonl_file) or not os.path.exists(args.tsv_file):
print('Eine der Eingabedateien wurde nicht gefunden.', file=sys.stderr)
exit(1)
chunksize = 20000
# GND-IDs in Set laden; detail-relevante IDs zusätzlich separat halten
DETAIL_TYPES = frozenset({'person', 'corporate', 'work', 'collection', 'subject', 'geo'})
haab_gnd = set()
detail_gnd = set()
with open(args.tsv_file, encoding='utf-8') as f:
for line in f:
parts = line.rstrip('\n').split('\t')
if not parts or not parts[0]:
continue
gnd_id = parts[0]
haab_gnd.add(gnd_id)
if len(parts) > 3 and parts[3] in DETAIL_TYPES:
detail_gnd.add(gnd_id)
def extract_auth(df, basecol, newcol):
def get_auth(item):
if 'id' in item:
gnd_id = item['id'].replace('https://d-nb.info/gnd/', '')
if gnd_id in detail_gnd:
suffix = 'detail'
elif gnd_id in haab_gnd:
suffix = 'intern'
else:
suffix = 'extern'
return f"{gnd_id}@{item['label']}@{suffix}"
return None
def process_list(x):
if not isinstance(x, list):
return None
result = [r for r in (get_auth(item) for item in x) if r]
return result if result else None
df[newcol] = [process_list(x) for x in df[basecol]]
def extract_name(df, basecol, newcol):
def get_name(item):
fields = ['forename', 'counting', 'prefix', 'surname', 'personalName', 'nameAddition']
parts = [
' '.join(v.strip() for v in item[f] if v)
for f in fields if f in item and item[f]
]
name = ' '.join(parts).strip()
return name if name else None
def process_list(x):
if not isinstance(x, list):
return None
result = [r for r in (get_name(item) for item in x) if r]
return result if result else None
df[newcol] = [process_list(x) for x in df[basecol]]
def process_chunk(df):
col = "accordingWork"
if col in df.columns:
extract_auth(df, col, 'accordingWork_str_mv')
df.drop(col, axis=1, inplace=True)
col = "associatedDate"
if col in df.columns:
df = df.rename(columns={col: 'associatedDate_str_mv'})
col = "biographicalOrHistoricalInformation"
if col in df.columns:
df = df.rename(columns={col: 'biographicalOrHistoricalInformation_txt_mv'})
col = "broaderTermGeneral"
if col in df.columns:
extract_auth(df, col, 'broaderTermGeneral_str_mv')
df.drop(col, axis=1, inplace=True)
col = "broaderTermInstantial"
if col in df.columns:
extract_auth(df, col, 'broaderTermInstantial_str_mv')
df.drop(col, axis=1, inplace=True)
col = "broaderTermPartitive"
if col in df.columns:
extract_auth(df, col, 'broaderTermPartitive_str_mv')
df.drop(col, axis=1, inplace=True)
col = "collector"
if col in df.columns:
extract_auth(df, col, 'collector_str_mv')
df.drop(col, axis=1, inplace=True)
col = "contributingCorporateBody"
if col in df.columns:
extract_auth(df, col, 'contributingCorporateBody_str_mv')
df.drop(col, axis=1, inplace=True)
col = "contributingPerson"
if col in df.columns:
extract_auth(df, col, 'contributingPerson_str_mv')
df.drop(col, axis=1, inplace=True)
col = "dateOfProduction"
if col in df.columns:
df = df.rename(columns={col: 'dateOfProduction_str_mv'})
col = "dateOfTermination"
if col in df.columns:
df = df.rename(columns={col: 'dateOfTermination_str_mv'})
col = "gndSubjectCategory" # .label
if col in df.columns:
df = df.rename(columns={col: 'field_of_activity'})
df['field_of_activity'] = [
[item['label'] for item in x] if isinstance(x, list) else None
for x in df['field_of_activity']
]
col = "formerOwner"
if col in df.columns:
extract_auth(df, col, 'formerOwner_str_mv')
df.drop(col, axis=1, inplace=True)
col = "geographicAreaCode" # .label
if col in df.columns:
df = df.rename(columns={col: 'geographicAreaCode_str_mv'})
df['geographicAreaCode_str_mv'] = [
[item['label'] for item in x] if isinstance(x, list) else None
for x in df['geographicAreaCode_str_mv']
]
col = "gndIdentifier"
if col in df.columns:
df = df.rename(columns={col: 'id'})
col = "homepage" # .id
if col in df.columns:
df = df.rename(columns={col: 'homepage_str_mv'})
df['homepage_str_mv'] = [
[item['id'] for item in x] if isinstance(x, list) else None
for x in df['homepage_str_mv']
]
col = "owner"
if col in df.columns:
extract_auth(df, col, 'owner_str_mv')
df.drop(col, axis=1, inplace=True)
col = "placeOfManufacture"
if col in df.columns:
extract_auth(df, col, 'placeOfManufacture_str_mv')
df.drop(col, axis=1, inplace=True)
col = "placeOfCustody"
if col in df.columns:
extract_auth(df, col, 'placeOfCustody_str_mv')
df.drop(col, axis=1, inplace=True)
col = "precedingWork"
if col in df.columns:
extract_auth(df, col, 'precedingWork_str_mv')
df.drop(col, axis=1, inplace=True)
col = "preferredName"
if col in df.columns:
df = df.rename(columns={col: 'heading'})
col = "relatedPerson"
if col in df.columns:
extract_auth(df, col, 'relatedPerson_str_mv')
df.drop(col, axis=1, inplace=True)
col = "relatedPlaceOrGeographicName"
if col in df.columns:
extract_auth(df, col, 'relatedPlaceOrGeographicName_str_mv')
df.drop(col, axis=1, inplace=True)
col = "relatedWork"
if col in df.columns:
extract_auth(df, col, 'relatedWork_str_mv')
df.drop(col, axis=1, inplace=True)
col = "sameAs" # .id
if col in df.columns:
df = df.rename(columns={col: 'see_also'})
df['see_also'] = [
[item['id'] for item in x] if isinstance(x, list) else None
for x in df['see_also']
]
col = "succeedingWork"
if col in df.columns:
extract_auth(df, col, 'succeedingWork_str_mv')
df.drop(col, axis=1, inplace=True)
col = "topic"
if col in df.columns:
extract_auth(df, col, 'topic_str_mv')
df.drop(col, axis=1, inplace=True)
col = "type" # ohne "AuthorityResource"
if col in df.columns:
df = df.rename(columns={col: 'type_str_mv'})
df['type_str_mv'] = df['type_str_mv'].apply(
lambda x: [v for v in x if v != "AuthorityResource"] if isinstance(x, list) else x
)
col = "variantName"
if col in df.columns:
df = df.rename(columns={col: 'use_for'})
# record_type setzen
df['record_type'] = 'collection'
# Spaltenreihenfolge: id zuerst, dann alphabetisch
cols = ['id'] + sorted([c for c in df.columns if c != 'id'])
df = df[cols]
# allfields: alle Feldinhalte mit Leerzeichen getrennt
def join_allfields(row):
values = []
for val in row:
if isinstance(val, list):
values.extend([str(v) for v in val])
elif pd.notna(val):
values.append(str(val))
return ' '.join(values)
df['allfields'] = df.apply(join_allfields, axis=1)
# Als JSON-Lines ohne null auf Stdout
for rec in df.to_dict(orient='records'):
# Entferne NaN-Werte aus dem Dictionary
clean_rec = {}
for k, v in rec.items():
if isinstance(v, list):
# Sicherstellen, dass Solr nur Strings und kein verschachteltes JSON erhält
flat_list = []
for item in v:
if isinstance(item, (dict, list)):
flat_list.append(json.dumps(item, ensure_ascii=False))
else:
flat_list.append(item)
clean_rec[k] = flat_list
elif pd.notna(v):
clean_rec[k] = v
print(json.dumps(clean_rec, ensure_ascii=False))
for chunk in pd.read_json(args.jsonl_file, lines=True, compression='gzip', chunksize=chunksize):
process_chunk(chunk)Code: Daten in VuFind-Solr laden
curl --silent -d '{ "delete": {"query":"*:*"} }' \
'http://localhost:8983/solr/authority/update?commit=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-collection.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-conference.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-corporate.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-family.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-geo.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-person.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-provenance.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-subject.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-work.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent --upload-file 'transformed-title.jsonl' \
'http://localhost:8983/solr/authority/update/json/docs?overwrite=true' \
-X POST -H 'Content-Type: application/json'
curl --silent 'http://localhost:8983/solr/authority/update?commit=true&optimize=true'Mapping GND-Ontologie -> VuFind
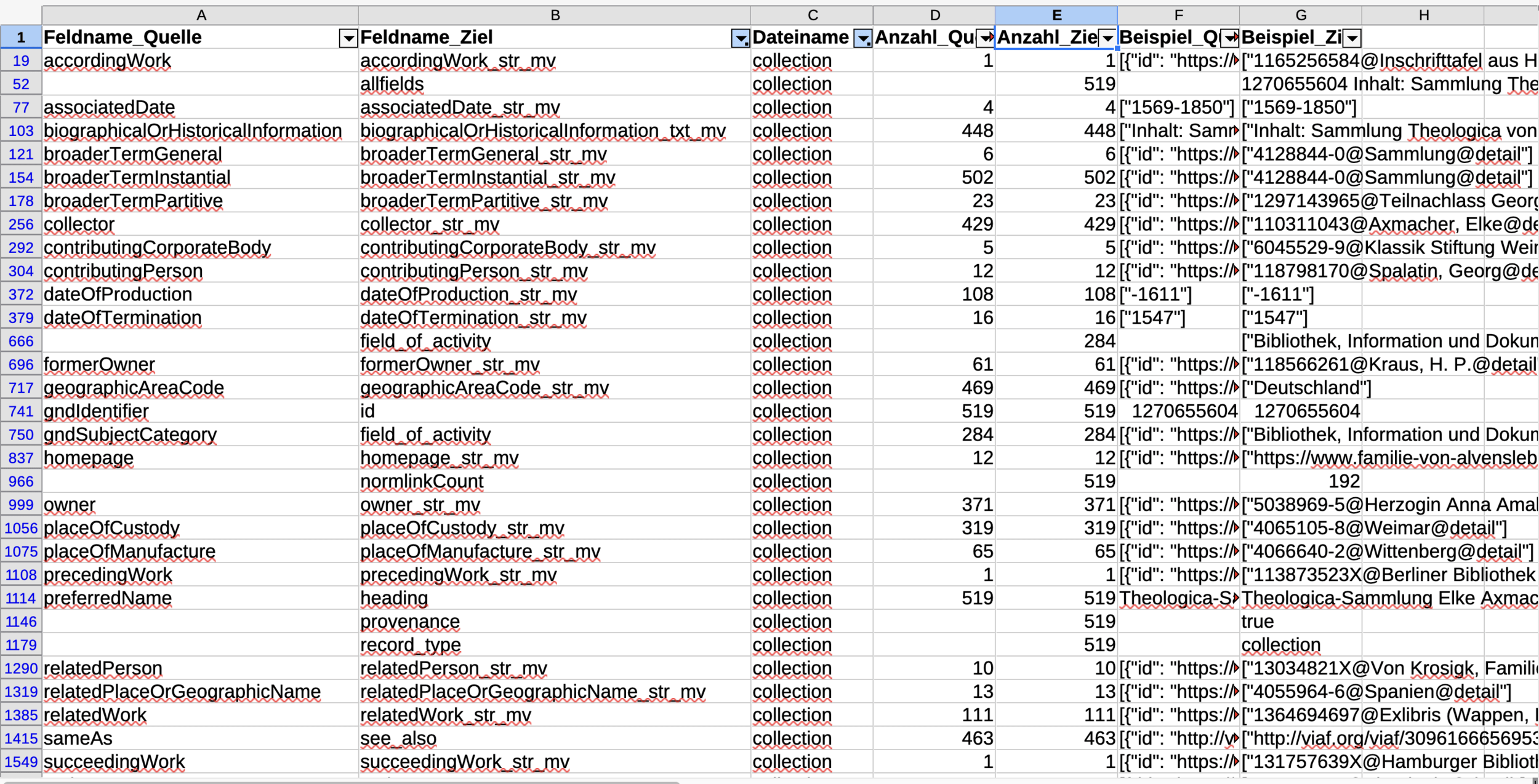
K10plus-Zentral
-
Beschränkung auf 150 Anfragen/Minute ist sehr limitierend
-
Allgemeine Geschwindigkeit durch aggressive Bots in letzter Zeit stark eingeschränkt
-
Kleiner Trick: Autovervollständigung des Titels auch über Normdatenindex, um Requests zu vermeiden
-
Täglich eine Abfrage über Facet-Query
-
Speicherung aller 4 Mio. Titel in einem separaten Feld im Normdatenindex
-
Todo vor Freischaltung (geplant für Juni)
-
Umstellung der Suchlinks in der Seitenleiste der Normdaten-Detailseiten auf "echte" VuFind-Filter (sichtbar, abwählbar)
-
Umstellung der Normdaten-Links auf den bibliographischen Detailseiten
-
Ergänzung weiterer, seltener belegter Felder auf den Normdaten-Detailseiten
-
Attributionsangabe bei Bildern aus Wikimedia Commons
-
...