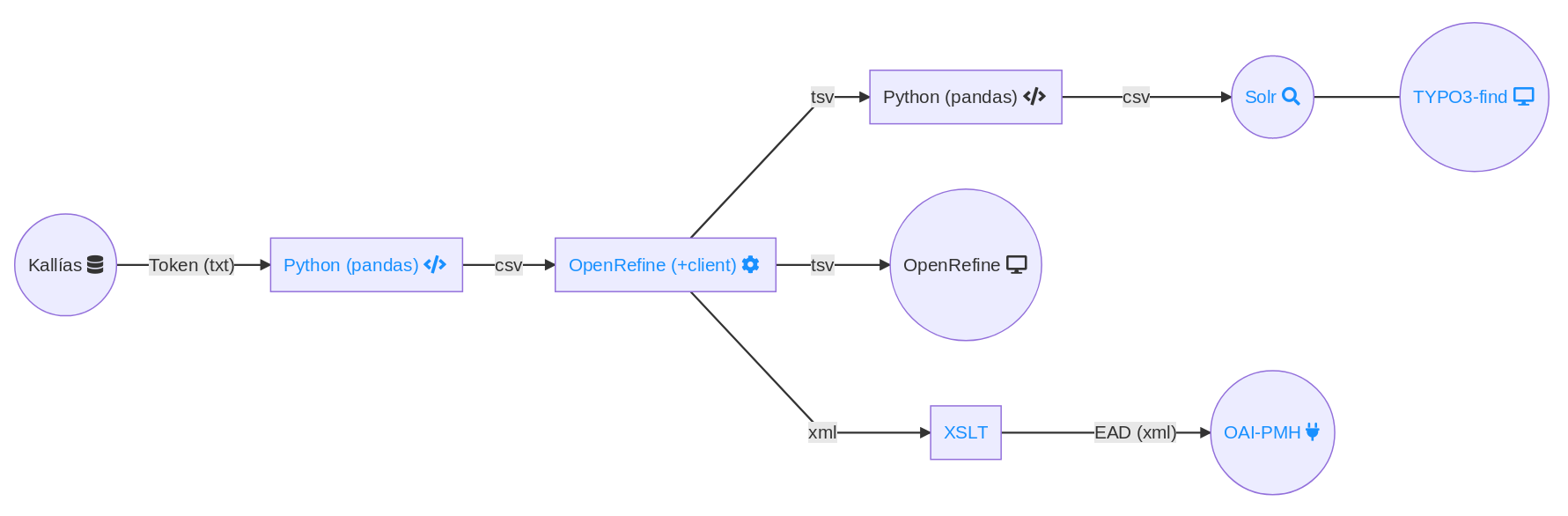
Aus dem lokalen Bibliotheksmanagementsystem Kallías (aDIS/BMS) werden alle Daten im proprietären Format aDIS-Token (Textdateien mit festen Spaltenbreiten) exportiert. Es handelt sich um eine relationale Datenstruktur, in der Medien, Exemplare, Normdaten, Erwerbungsdaten, Schlagwörter und Thesaurus in insgesamt 12 Teilbeständen abgebildet werden. Nach dem Export durch aDIS/BMS werden die Textdateien mit awk und perl vorprozessiert, u.a. um die Form von Zeilenumbrüchen und Mehrfachbelegungen nachzubearbeiten.
Der erste größere Verarbeitungsschritt erfolgt mit der Python Data Analysis Library (pandas). Ein Python Script liest die Token-Dateien ein, transformiert sie und speichert eine kommaseparierte Textdatei (.csv) pro Teilbestand. Folgende Transformationen werden durchgeführt:
Im zweiten Schritt, in dem Python (pandas) zum Einsatz kommt, werden in den Normdaten enthaltene Synonyme an die Datensätze der Teilbestände zugespielt. Dies erfolgt mit individuellen Python Scripten, die ebenfalls die Python Data Analysis Library (pandas) verwenden. Das Ergebnis wird als kommaseparierte Datei (.csv) gespeichert.
Im Mittelpunkt steht die Datenverarbeitung mit OpenRefine. Die Prozesse erfolgen automatisiert über einen ad hoc gestarteten OpenRefine-Server und eine frei verfügbare Client-Software. Hier werden die Daten für den Suchindex aufbereitet und auch inhaltlich angereichert und transformiert. Folgende Transformationen werden durchgeführt:
Die Ergebnisse werden als tabseparierte Datei (.tsv) für die spätere Indexierung im Suchindex exportiert und auch in einen dauerhaften OpenRefine-Server zur Ansicht geladen. Zusätzlich wird für die Generierung von EAD aus den Beständen und Handschriften eine hierarchisch sortierte Gesamtliste erstellt, die über ein komplexes OpenRefine-Template als XML ausgegeben wird.
Im Mitarbeiternetz wird ein dauerhafter OpenRefine-Server betrieben, dessen Oberfläche für alle Projektbeteiligten und weitere Kolleg*innen über den Browser zugänglich ist. Bei jeder Datenprozessierung werden die enthaltenen Daten aktualisiert. Anpassungen der Konfiguration können in der grafischen Oberfläche von OpenRefine erprobt und dann in den Konfigurationsdateien für die Automatisierung gespeichert werden. Außerdem wird der Zugriff auf die Katalogdaten in OpenRefine für weitere hausinterne Zwecke, z.B. für die Digitalisierung, eingesetzt.
Fork von OpenRefine: https://github.com/opencultureconsulting/OpenRefine
OpenRefine-client: https://github.com/opencultureconsulting/openrefine-client
Als Suchindex wird Apache Solr in der aktuellen Version verwendet. Die im vorigen Schritt erstellten CSV-Dateien werden via curl parallel über die CSV-Update-Schnittstelle von Solr indexiert. Durch Copyfield-Regeln werden die Inhalte von allen zu durchsuchenden Feldern in ein zusätzliches Feld kopiert. Für das Relevanzranking wird dieses Feld gering und etwa 15 weitere Felder (u.a. Felder für die Trefferliste, Namensfelder und ausgewählte Facetten) mittel bis hoch gewichtet. Aus den in OpenRefine für die Autovervollständigung generierten Feldern wird außerdem ein Suggester Service gebaut.
http://lucene.apache.org/solr/
Die Katalogoberfläche ist mit der TYPO3-Erweiterung find der SUB Göttingen realisiert. Die Templates für die Trefferliste wurden so angepasst, dass zusätzlich stets zwei Normdatentreffer für die Suche angezeigt werden. Die Templates für die Detailseiten wurden spezifisch für die Teilbestände entwickelt. Es wurden auch kleinere Erweiterungen für TYPO3-find entwickelt, wie beispielsweise eine eigene Histogramm-Facette. Die Autovervollständigung im Suchschlitz ist mit einem Fork der Software jQuery Tokeninput und eigenen TYPO3-eID-Scripten realisiert.
https://github.com/subugoe/typo3-find/
http://loopj.com/jquery-tokeninput/
Der Hauptteil der Generierung von EAD/XML erfolgt im vorigen Schritt in OpenRefine. Aufgrund der komplexen Verschachtelung im EAD-Format ist es jedoch mit dem OpenRefine-Template nicht möglich, valides EAD zu erzeugen, so dass hier noch Nacharbeiten mit XSLT erforderlich sind. Der Gesamtprozess ist in einer Präsentation von 2017 erläutert:
https://felixlohmeier.de/slides/2017-05-05_dini-ag-kim_ead-lightning-talk.html
Die generierten EAD/XML-Dateien werden über eine OAI-PMH-Schnittstelle bereitgestellt. Dazu wurde im Projekt ein dateibasierter OAI-PMH Data Provider geforkt und weiterentwickelt: